197 min to read
Estimating COVID-19s transmission rates in Georgia
Facts not Fear
What do R0 values mean?¶
Three possibilities exist for the potential transmission or decline of a disease, depending on its R0 value:
- If R0 is less than 1, each existing infection causes less than one new infection. In this case, the disease will decline and eventually die out.
- If R0 equals 1, each existing infection causes one new infection. The disease will stay alive and stable, but there wont be an outbreak or an epidemic.
- If R0 is more than 1, each existing infection causes more than one new infection. The disease will be transmitted between people, and there may be an outbreak or epidemic.
In the current pandemic people can be overwhelmed by the amoun of data being thrown at them on the news, social media and other connects. This post breaks down a method to predict the new cases in my home state of Georgia based on the number of cases from the previous day
I have done my best to display visual what the code does. Also I try my best to make the math less scary with simple definitions
Definition of terms:
Lambda- is defined as an asymmetrical measure of assocation that is suitable for use with nominal variables, it will range from 0 to 1. Lambda provides us with an indication of the strength of the relationship betewen independent and dependet variables.
Sigma - is a statistical measurement of variability, showing how much variation exists from a statistical average. It measures how far an observed data deviates from the mean or average.
Gamma- tells us how closely tow paira of data points match, it asscocates these points and defines the strenght of the accociattion.
Import python libraries and Data¶
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from matplotlib.dates import date2num, num2date
from matplotlib import dates as mdates
from matplotlib import ticker
from matplotlib.colors import ListedColormap
from matplotlib.patches import Patch
from scipy import stats as sps
from scipy.interpolate import interp1d
from scipy import stats as sps
from scipy.interpolate import interp1d
from IPython.display import clear_output
url = 'https://covidtracking.com/api/v1/states/daily.csv'
states = pd.read_csv(url,
usecols=['date', 'state', 'positive'],
parse_dates=['date'],
index_col=['state', 'date'],
squeeze=True).sort_index()
Approach¶
Every day, we learn how many more people have COVID-19. This new case count gives us a clue about the current value of $R_t$. We also, figure that the value of $R_t$ today is related to the value of $R_{t-1}$ (yesterday's value) and every previous value of $R_{t-m}$ for that matter.
This is Bayes' Theorem as we'll use it:
$$ P(R_t|k)=\frac{P(k|R_t)\cdot P(R_t)}{P(k)} $$This says that, having seen $k$ new cases, we believe the distribution of $R_t$ is equal to:
- The likelihood of seeing $k$ new cases given $R_t$ times
- The prior beliefs of the value of $P(R_t)$ without the data
- divided by the probability of seeing this many cases in general
The next part is a terse expression which makes it tricky. By giving it a column for $k$ and a 'row' for lambda it will evaluate the pmf over both and produce an array that has $k$ rows and lambda columns.
k = 20
lam = np.linspace(1, 45, 90)
likelihood = pd.Series(data=sps.poisson.pmf(k, lam),
index=pd.Index(lam, name='$\lambda$'),
name='lambda')
likelihood.plot(title=r'Data Visualizations of Likelihood $P\left(k_t=20|\lambda\right)$', figsize=(6,2.5));

Choosing a Likelihood Function $P\left(k_t|R_t\right)$¶
Next we will look at a liklihood function that we can use to see how likely we are to see k new cases in a given value like $R_t$. When the need to create a model that shows 'arrivals' over a period of time often the Poisson Distribution is used. We will use $\lambda$ to represent the arrival rate of new cases per day.
Poisson, is a discrete probability distribution that expresses the probability of a given number of events occurring in a fixed interval of time or space if these events occur with a known constant mean rate and independently of the time since the last event.
This means that the Poisson distribution can be used to analyze the probability of various events that can lead to how many new cases of Covid-19 there will be in a day. We can calculate the probability of a lull in the number of new cases and well as the probabilty of a spike in the reported new cases. This information can then be used to determine what safety measures should be put in place or removed.
An example of the Poisson Distribution is shown below. Using the probabilty of k and $\lambda$, where k is the number of new cases and $\lambda$ is the potential number of new cases. Assigning four random values for $\lambda$ in intervals of 10's the graph shows the probablity in standard deviation of each of the values for $\lambda$.
# Column vector of k
k = np.arange(0, 70)[:, None]
# Different values of Lambda
lambdas = [10, 20, 30, 40]
# Evaluated the Probability Mass Function (remember: poisson is discrete)
y = sps.poisson.pmf(k, lambdas)
# Show the resulting shape
print(y.shape)
This does not really show the relationship that is between K and $\lambda$ as only a column was created for k and a row for $\lambda$, but it does evaluate the probability math function over both to create an array making this an effiecient way of producing multiple distributions simultaneously. Another way of applying the Poisson distribution with a better visual is shown below.
fig, ax = plt.subplots(figsize=(6,2.5))
ax.set(title='Visual Example Poisson Distribution of Cases\n $p(k|\lambda)$')
plt.plot(k, y,
marker='o',
markersize=3,
lw=0)
plt.legend(title="$\lambda$", labels=lambdas);

The Poisson distribution says that if you think you're going to have $\lambda$ cases per day, you'll probably get that many, plus or minus some variation based on chance.
But in our case, we know there have been $k$ cases and we need to know what the most likely value of $\lambda$ is. In order to do this, we fix $k$ in place while varying $\lambda$. This is called the likelihood function.
For example, imagine we observe $k=20$ new cases, and we want to know how likely each $\lambda$ is:
k = 20
lam = np.linspace(1, 45, 90)
likelihood = pd.Series(data=sps.poisson.pmf(k, lam),
index=pd.Index(lam, name='$\lambda$'),
name='lambda')
likelihood.plot(title=r'Data Visualizations of Likelihood $P\left(k_t=20|\lambda\right)$', figsize=(6,2.5));
This graph is pretty straight forward to what we inputed. We will see 20 cases, so the most likely $\lambda$ is also 20, but there is the possibilty that it will fall between 17 and 21 as we saw 20 new cases by chance. It also shows that the $\lambda$ is not very likely to be 40. Now we have the parameters for $\lambda$, but we want parameters for $R_t$, this means that we need to connect $\lambda$ and $R_t$. First we must realize that there is a connection between the two, however the derivation is beyond the scope of this notebook.
Evaluating the Likelihood Function¶
To continue our example, let's imagine a sample of new case counts $k$. What is the likelihood of different values of $R_t$ on each of those days?
# Create an Array for teting intervals
k = np.array([20, 40, 55, 90])
# We create an array for every possible value of Rt
R_T_MAX = 12
r_t_range = np.linspace(0, R_T_MAX, R_T_MAX*100+1)
# Gamma is 1/serial interval
# The serial interval of an infectious disease represents
# the duration between symptom onset of a primary case and symptom onset of its secondary cases.
# A good evidence base for such values is essential, because they allow investigators to identify
# epidemiologic links between cases and serve as an important parameter in epidemic transmission models
# used to design infection control strategies.
# https://wwwnc.cdc.gov/eid/article/26/7/20-0282_article
# https://www.nejm.org/doi/full/10.1056/NEJMoa2001316
GAMMA = 1/7
# Map Rt into lambda so we can substitute it into the equation below
# Note that we have N-1 lambdas because on the first day of an outbreak
# you do not know what to expect.
lam = k[:-1] * np.exp(GAMMA * (r_t_range[:, None] - 1))
# Evaluate the likelihood on each day and normalize sum of each day to 1.0
likelihood_r_t = sps.poisson.pmf(k[1:], lam)
likelihood_r_t /= np.sum(likelihood_r_t, axis=0)
# Plot it
ax = pd.DataFrame(
data = likelihood_r_t,
index = r_t_range
).plot(
title='Likelihood of $R_t$ given $k$',
xlim=(0,10),
figsize=(6,2.5)
)
ax.legend(labels=k[1:], title='New Cases')
ax.set_xlabel('$R_t$');

This graph shows that each day there is an independent guess for $R_t$, and the goal is have a joining of the information we already have from previous days with the current day, so we must go back to Bayes' Theorem and update our hypothesis.
Performing the Bayesian Update¶
As more information becomes available we need to update the probabilities hypothesis of the number of new cases that will be seen each day. This is also called the Bayesian update. To perform this update we need to multiply the likelihood of new cases by the prior(before the data) without the use of the Gaussian or the distribution of $P(R_{t-1}, \sigma)$ to get the posteriors(after the data). Let's do that using the cumulative product of each successive day:
posteriors = likelihood_r_t.cumprod(axis=1)
posteriors = posteriors / np.sum(posteriors, axis=0)
columns = pd.Index(range(1, posteriors.shape[1]+1), name='Day')
posteriors = pd.DataFrame(
data = posteriors,
index = r_t_range,
columns = columns)
ax = posteriors.plot(
title='Posterior $P(R_t|k)$',
xlim=(0,10),
figsize=(6,2.5)
)
ax.legend(title='Day')
ax.set_xlabel('$R_t$');

You can see that on Day 1, our posterior matches Day 1's likelihood from above, because it is the only information that we have for Day 1. When we update the prior using the information we have gathered for Day 2, teh curve moves left but not as far left as the likelihood above. This is due to Bayesian updating the information from both days and then effectively averaging teh two. Day 3's likelihood is in between Day 1 and Day 2 so you can see the small shift to the right, but more importantly you see the distribution narrow, proving more belief that Day 3 is closer to the true value of $R_t$.
The Human Developmemt Index (HDI) indicates which points of a distribution are most credible, and which cover most of the distribution. Thus, the HDI summarizes the distribution by specifying an interval that spans most of the distribution, say 95% of it, such that every point inside the interval has higher credibility than any point outside the interval.
What is the most likely value of $R_t$ each day?¶
most_likely_values = posteriors.idxmax(axis=0)
most_likely_values
Obtain the highest density intervals for $R_t$¶
def highest_density_interval(pmf, p=.9, debug=False):
# If we pass a DataFrame, just call this recursively on the columns
if(isinstance(pmf, pd.DataFrame)):
return pd.DataFrame([highest_density_interval(pmf[col], p=p) for col in pmf],
index=pmf.columns)
cumsum = np.cumsum(pmf.values)
# N x N matrix of total probability mass for each low, high
total_p = cumsum - cumsum[:, None]
# Return all indices with total_p > p
lows, highs = (total_p > p).nonzero()
# Find the smallest range (highest density)
best = (highs - lows).argmin()
low = pmf.index[lows[best]]
high = pmf.index[highs[best]]
return pd.Series([low, high],
index=[f'Low_{p*100:.0f}',
f'High_{p*100:.0f}'])
hdi = highest_density_interval(posteriors, debug=True)
hdi.tail()
Plot both the most likely values for $R_t$ and the HDIs over time. This is the most useful representation as it shows how our beliefs change with every day.¶
ax = most_likely_values.plot(marker='o',
label='Most Likely',
title=f'$R_t$ by day',
c='k',
markersize=4)
ax.fill_between(hdi.index,
hdi['Low_90'],
hdi['High_90'],
color='k',
alpha=.1,
lw=0,
label='HDI')
ax.legend();

state_name = 'GA'
def prepare_cases(cases, cutoff=25):
new_cases = cases.diff()
smoothed = new_cases.rolling(7,
win_type='gaussian',
min_periods=1,
center=True).mean(std=2).round()
idx_start = np.searchsorted(smoothed, cutoff)
smoothed = smoothed.iloc[idx_start:]
original = new_cases.loc[smoothed.index]
return original, smoothed
cases = states.xs(state_name).rename(f"{state_name} cases")
original, smoothed = prepare_cases(cases)
original.plot(title=f"{state_name} New Cases per Day",
c='k',
linestyle=':',
alpha=.5,
label='Actual',
legend=True,
figsize=(500/72, 300/72))
ax = smoothed.plot(label='Smoothed',
legend=True)
ax.get_figure().set_facecolor('w')

Function for Calculating the Posteriors¶
"Posterior", in this context, means after taking into account the relevant evidences related to the particular case being examined. For instance, there is a ("non-posterior") probability of a person finding buried treasure if they dig in a random spot, and a posterior probability of finding buried treasure if they dig in a spot where their metal detector rings. There are five steps to calculate the posteriors as notated in the below code
def get_posteriors(sr, sigma=0.15):
# (1) Calculate Lambda
lam = sr[:-1].values * np.exp(GAMMA * (r_t_range[:, None] - 1))
# (2) Calculate each day's likelihood
likelihoods = pd.DataFrame(
data = sps.poisson.pmf(sr[1:].values, lam),
index = r_t_range,
columns = sr.index[1:])
# (3) Create the Gaussian Matrix
process_matrix = sps.norm(loc=r_t_range,
scale=sigma
).pdf(r_t_range[:, None])
# (3a) Normalize all rows to sum to 1
process_matrix /= process_matrix.sum(axis=0)
# (4) Calculate the initial prior
#prior0 = sps.gamma(a=4).pdf(r_t_range)
prior0 = np.ones_like(r_t_range)/len(r_t_range)
prior0 /= prior0.sum()
# Create a DataFrame that will hold our posteriors for each day
# Insert our prior as the first posterior.
posteriors = pd.DataFrame(
index=r_t_range,
columns=sr.index,
data={sr.index[0]: prior0}
)
log_likelihood = 0.0
# (5) Iteratively apply Bayes' rule
for previous_day, current_day in zip(sr.index[:-1], sr.index[1:]):
#(5a) Calculate the new prior
current_prior = process_matrix @ posteriors[previous_day]
#(5b) Calculate the numerator of Bayes' Rule: P(k|R_t)P(R_t)
numerator = likelihoods[current_day] * current_prior
#(5c) Calcluate the denominator of Bayes' Rule P(k)
denominator = np.sum(numerator)
# Execute full Bayes' Rule
posteriors[current_day] = numerator/denominator
# Add to the running sum of log likelihoods
log_likelihood += np.log(denominator)
return posteriors, log_likelihood
# fixing sigma to a value just for the example
posteriors, log_likelihood = get_posteriors(smoothed, sigma=.25)
Below you can see every day (row) of the posterior distribution plotted simultaneously. The posteriors start without much confidence (wide) and become progressively more confident (narrower) about the true value of $R_t$
ax = posteriors.plot(title=f'{state_name} - Daily Posterior for $R_t$',
legend=False,
lw=1,
c='k',
alpha=.3,
xlim=(0.4,6))
ax.set_xlabel('$R_t$');

Plotting in the Time Domain with Credible Intervals¶
def highest_density_interval(pmf, p=.9, debug=False):
# If we pass a DataFrame, just call this recursively on the columns
if(isinstance(pmf, pd.DataFrame)):
return pd.DataFrame([highest_density_interval(pmf[col], p=p) for col in pmf],
index=pmf.columns)
cumsum = np.cumsum(pmf.values)
# N x N matrix of total probability mass for each low, high
total_p = cumsum - cumsum[:, None]
# Return all indices with total_p > p
lows, highs = (total_p > p).nonzero()
# Find the smallest range (highest density)
best = (highs - lows).argmin()
low = pmf.index[lows[best]]
high = pmf.index[highs[best]]
return pd.Series([low, high],
index=[f'Low_{p*100:.0f}',
f'High_{p*100:.0f}'])
hdi = highest_density_interval(posteriors, debug=True)
hdi.tail()
# Note that this takes a while to execute - it's not the most efficient algorithm
hdis = highest_density_interval(posteriors, p=.9)
most_likely = posteriors.idxmax().rename('ML')
# Look into why you shift -1
result = pd.concat([most_likely, hdis], axis=1)
result.tail()
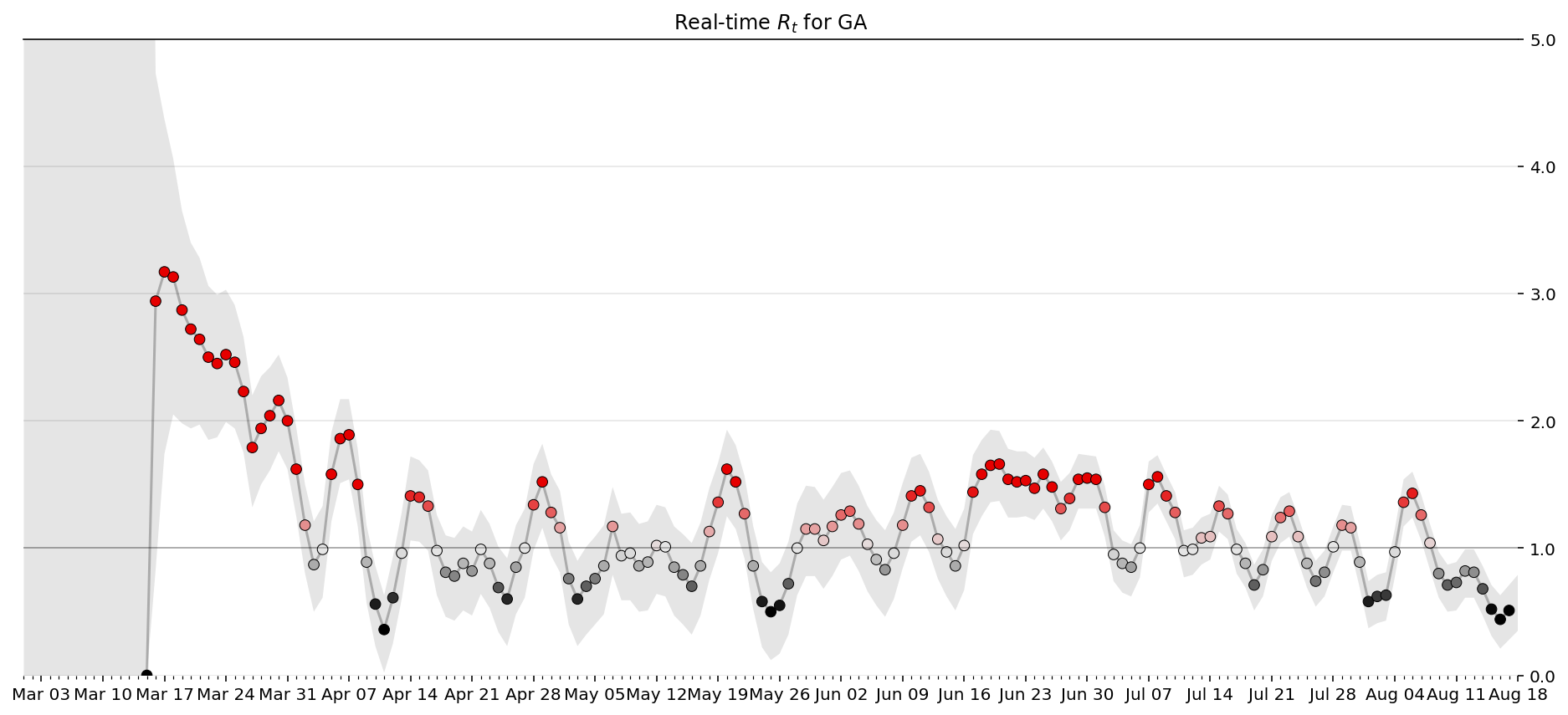
Real Time trasmission rates for Georiga¶
def plot_rt(result, ax, state_name):
ax.set_title(f"{state_name}")
# Colors
ABOVE = [1,0,0]
MIDDLE = [1,1,1]
BELOW = [0,0,0]
cmap = ListedColormap(np.r_[
np.linspace(BELOW,MIDDLE,25),
np.linspace(MIDDLE,ABOVE,25)
])
color_mapped = lambda y: np.clip(y, .5, 1.5)-.5
index = result['ML'].index.get_level_values('date')
values = result['ML'].values
# Plot dots and line
ax.plot(index, values, c='k', zorder=1, alpha=.25)
ax.scatter(index,
values,
s=40,
lw=.5,
c=cmap(color_mapped(values)),
edgecolors='k', zorder=2)
# Aesthetically, extrapolate credible interval by 1 day either side
lowfn = interp1d(date2num(index),
result['Low_90'].values,
bounds_error=False,
fill_value='extrapolate')
highfn = interp1d(date2num(index),
result['High_90'].values,
bounds_error=False,
fill_value='extrapolate')
extended = pd.date_range(start=pd.Timestamp('2020-03-01'),
end=index[-1]+pd.Timedelta(days=1))
ax.fill_between(extended,
lowfn(date2num(extended)),
highfn(date2num(extended)),
color='k',
alpha=.1,
lw=0,
zorder=3)
ax.axhline(1.0, c='k', lw=1, label='$R_t=1.0$', alpha=.25);
# Formatting
ax.xaxis.set_major_locator(mdates.MonthLocator())
ax.xaxis.set_major_formatter(mdates.DateFormatter('%b'))
ax.xaxis.set_minor_locator(mdates.DayLocator())
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_formatter(ticker.StrMethodFormatter("{x:.1f}"))
ax.yaxis.tick_right()
ax.spines['left'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.margins(0)
ax.grid(which='major', axis='y', c='k', alpha=.1, zorder=-2)
ax.margins(0)
ax.set_ylim(0.0, 5.0)
ax.set_xlim(pd.Timestamp('2020-03-01'), result.index.get_level_values('date')[-1]+pd.Timedelta(days=1))
fig.set_facecolor('w')
fig, ax = plt.subplots(figsize=(16,7))
plot_rt(result, ax, state_name)
ax.set_title(f'Real-time $R_t$ for {state_name}')
ax.xaxis.set_major_locator(mdates.WeekdayLocator())
ax.xaxis.set_major_formatter(mdates.DateFormatter('%b %d'))

The ispiration for this is based on Kevin Systrom post back in Apiril. As a data scientist I feel it is important to review and extent the work of others
See original post here: https://github.com/k-sys/covid-19/blob/master/Realtime%20R0.ipynb